알고리즘 특강을 들으면서 인상 깊었던 내용을 정리합니다.
자세한 개념보다는 알고리즘의 '이해' 그리고 '활용'(팁)에 중점을 두었습니다.
내용이 이상하다면 지적해주시면 감사하겠습니다. 👍
벌써 알고리즘 특강 3일차 입니다.
오늘 계속 조금씩 뭔가 빼먹으면서 문제를 풀었기에 틀릴 때가 많았습니다.
먼저 오늘 배웠던 것 중에 가장 어렵다고 느껴졌던 인덱스 트리에 대해 알아보겠습니다.
인덱스 트리 사용 이유
먼저 인덱스 트리를 사용하는 이유에 대해 알아보겠습니다.
한 개발자가 와서 저한테 이런 문제를 줬습니다.
이 배열 안에 있는 연속되는 숫자의 합을 구하는 프로그램을 구현해줘 😃
저는 여느때와 다름 없이
배열을 초기화여 입력값을 받고
숫자를 더할 배열를 범위를 입력받고 더했습니다.
for (int idx = start; idx <= end; idx++) {
sum += arr[idx];
}
그러자 그 개발자는 매우 화냈습니다.
이건 시간복잡도가 $O(n$)이잖아. 이건 안쓰지 😕
개발자 : 난 이미 $O(logN)$이 되는 프로그램이 있는데…
순수하게 for문으로 계산하는 것이 아닌 이진트리를 응용하면 훨씬 효율적으로 구할 수 있습니다.
인덱스 트리 용어, 트리 구조
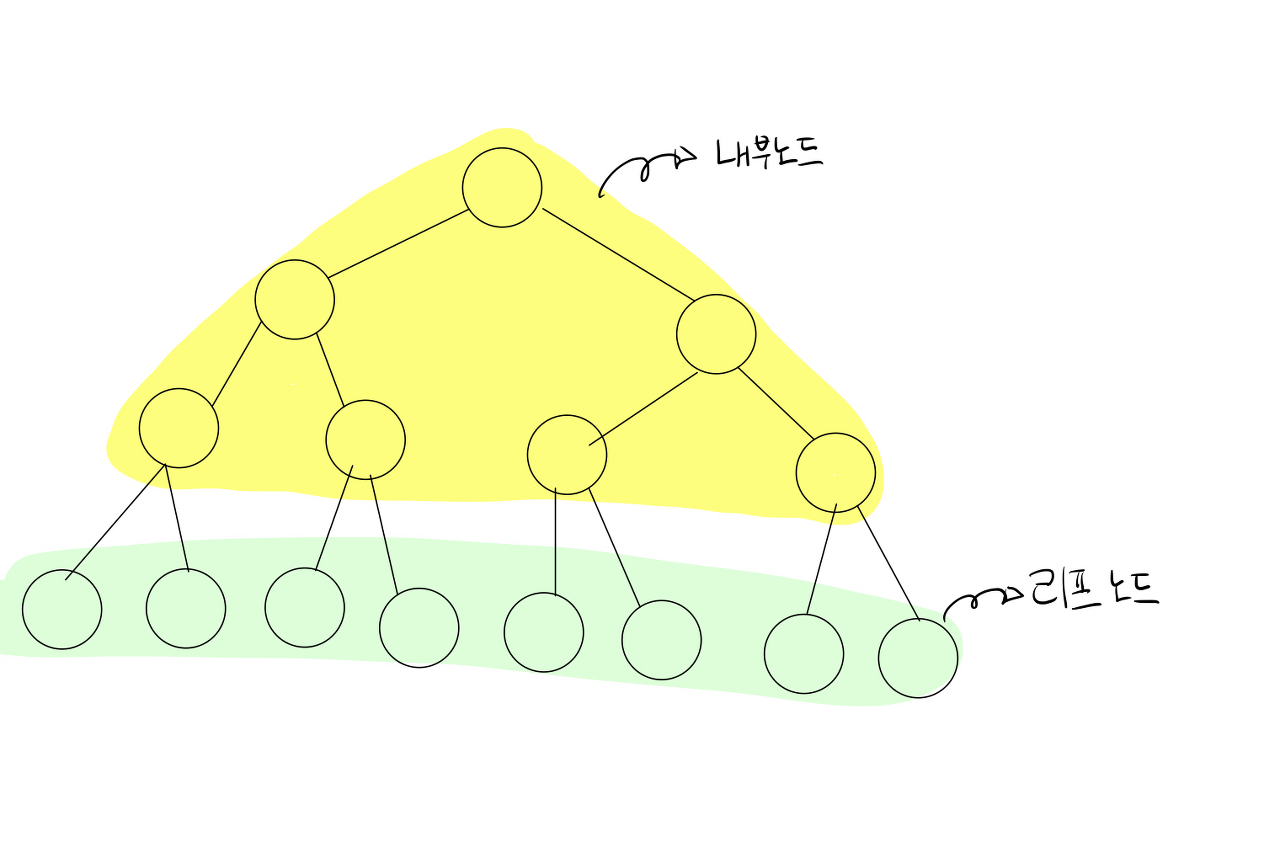
먼저 인덱스 트리는 다음과 같은 특징이 있습니다.
- 포화 이진트리 형태
- 리프 노드 : 배열에 적혀 있는 수
- 내부 노드 : 왼쪽 자식과 오른쪽 자식의 합
- 리프 노드의 개수가 N개 이상인 포화 이진트리는 높이가 최소 logN이다.
- 리프 노드의 개수가 N개 보다 많아 비어있는 공간이 발생할 경우 구조에 지장이 가지 않도록 초기값을 설정한다.
아래와 같이 맨 아래 줄을 리프 노드라고 하고 각각 ‘범위가 1이다’
위에 노란색인 내부 모드를 자식을 합쳐서 만든 것으로 ‘범위를 갖고’ 있습니다.
그렇다면 인덱스 트리로 구간의 합을 어떻게 구할 수 있을까요 ?
인덱스 트리를 이용하는데에 있어 Top-Down과 Bottom-Up 방식이 있습니다.
Top-Down (DFS 기반 트리 탐색 : 재귀 호출)
- Indexed Tree 개념을 그대로 코드로 수행
- 사람이 손으로 하는 방식과 유사
- 왼쪽 자식 = 2 * node, 오른쪽 자식 = 2 * node + 1 이용
- 가지치기 가능 (쿼리 필요 없을 때)
- x번째로 빠른 숫자 등 카운팅 쿼리 가능
Bottom-Up (반복문 기반 이동)
- Index의 홀짝 특성을 이용
- 부모 = node / 2 이용
- 코드가 단순
- 수행 속도가 미세하게 빠름
참고로, Bottom-Up으로 풀리지 않는 문제가 존재합니다.
Top-Down의 재귀 호출 때문에 Bottom-Up에 비해 미세하게 느리지만 큰 차이가 없으므로 Top-Down 방식만 알아보겠습니다.
인덱스 트리 - 구간의 합, 쿼리 수행 방법
먼저 그림을 보겠습니다.
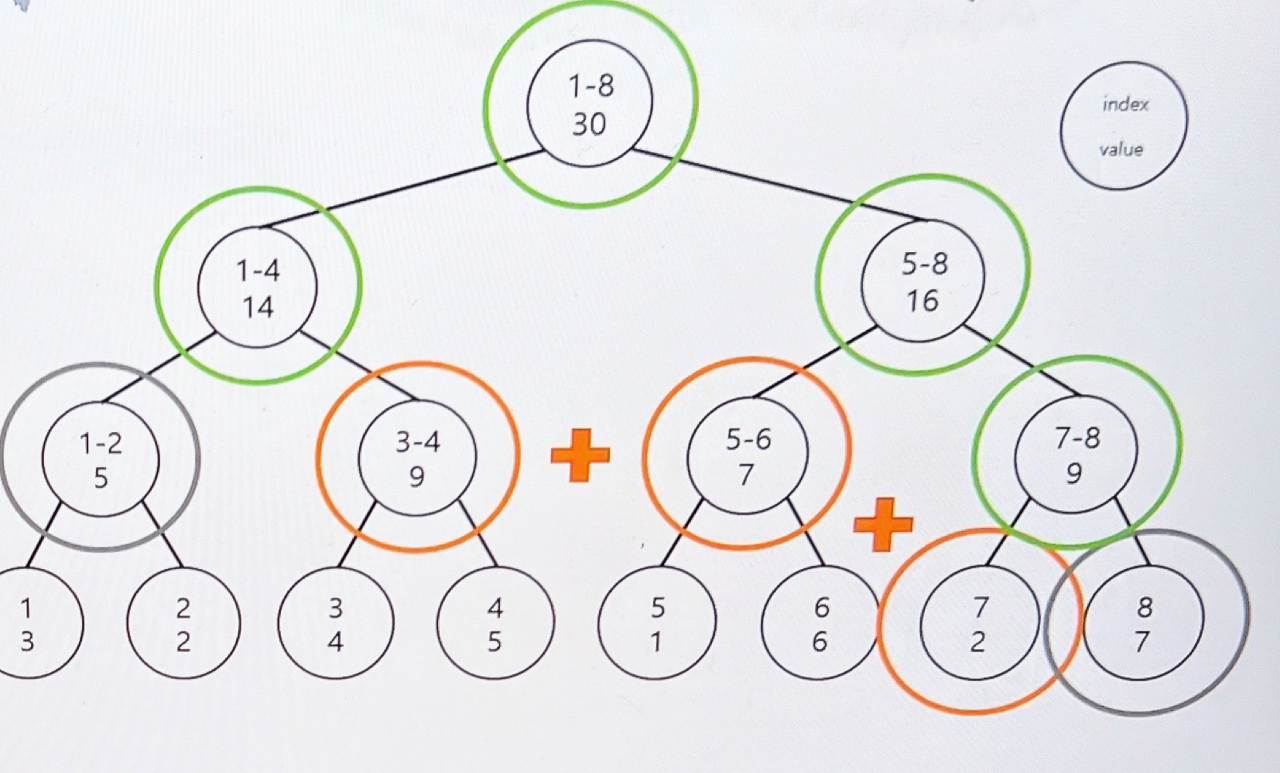
먼저 트리를 보면 한 노드에 범위와 값이 들어가 있는 것을 볼 수 있습니다.
내부 트리에 있는 각 노드는 자식 노드의 합입니다.
노드를 봤을 때 (1-4, 14)는 범위 1-4 까지 더한 값이 14라는 의미를 갖고 있습니다.
즉, 리프 트리에 값을 받아서 내부 트리를 채워주고 나서야 인덱스 트리를 시작하게 됩니다.
이후 탐색을 하게 되는데 저희가 3-4 범위의 합을 계산해달라고 하는 것이고
이를 Query(3, 4) 라고 작성하겠습니다.
Query(3, 4)는 아래와 같은 과정으로 검색하게 됩니다.
먼저 모든 범위의 합인 루트 노드에서 시작합니다.
다음에 루트 노드에서의 왼쪽 자식과 오른쪽 자식의 범위를 내가 찾을 범위와 비교 해줍니다.
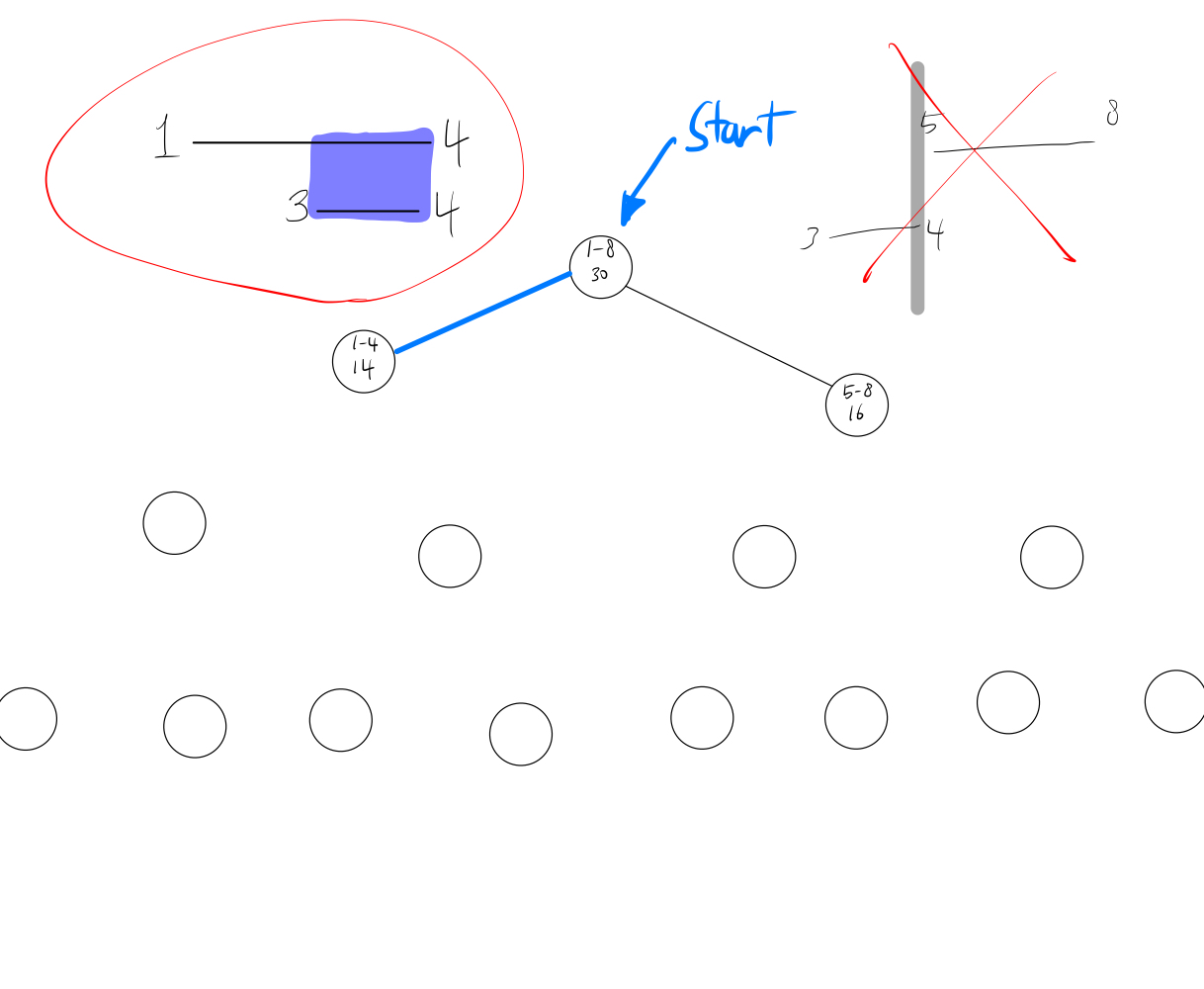
위 그림과 같이 우리가 찾는 (3, 4)는 오른쪽 자식 노드의 범위에는 전혀 포함되지않아 무시하고
왼쪽 노드에는 우리가 찾는 모든 범위가 포함되어 있으므로 왼쪽 노드로 향하게 됩니다.
왼쪽 노드로 향하면 이제 ((1, 4), 14)라는 노드에서 우리가 찾는 값을 찾을 수 없어다시 자식 노드들에게 탐색 일을 위임해줍니다.
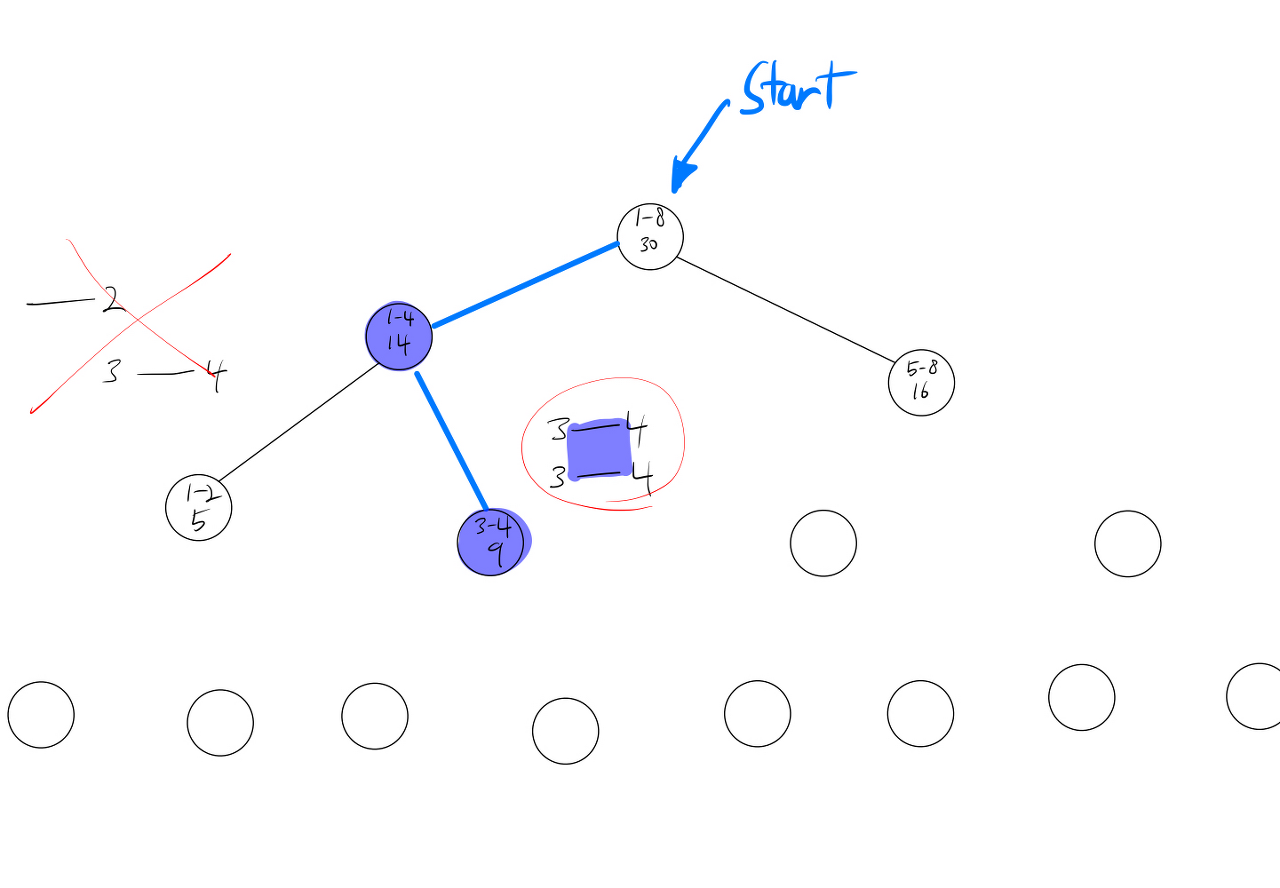
그리고 다음과 같이 오른쪽 자식 노드로 갔을 때 우리가 찾던 범위와 정확하게 맞는 (3, 4)의 범위 합을 갖고 있는 노드를 찾게 됩니다.
이로서 원하는 값을 9로 찾았으며 더 이상 탐색할 필요가 없어졌습니다.
우리는 계속 탐색하면서 ‘범위'를 가지고 판단하였습니다.
아래 그림은 범위에 대해서 어떤 식으로 처리해야함에 대해 기술된 그림입니다.
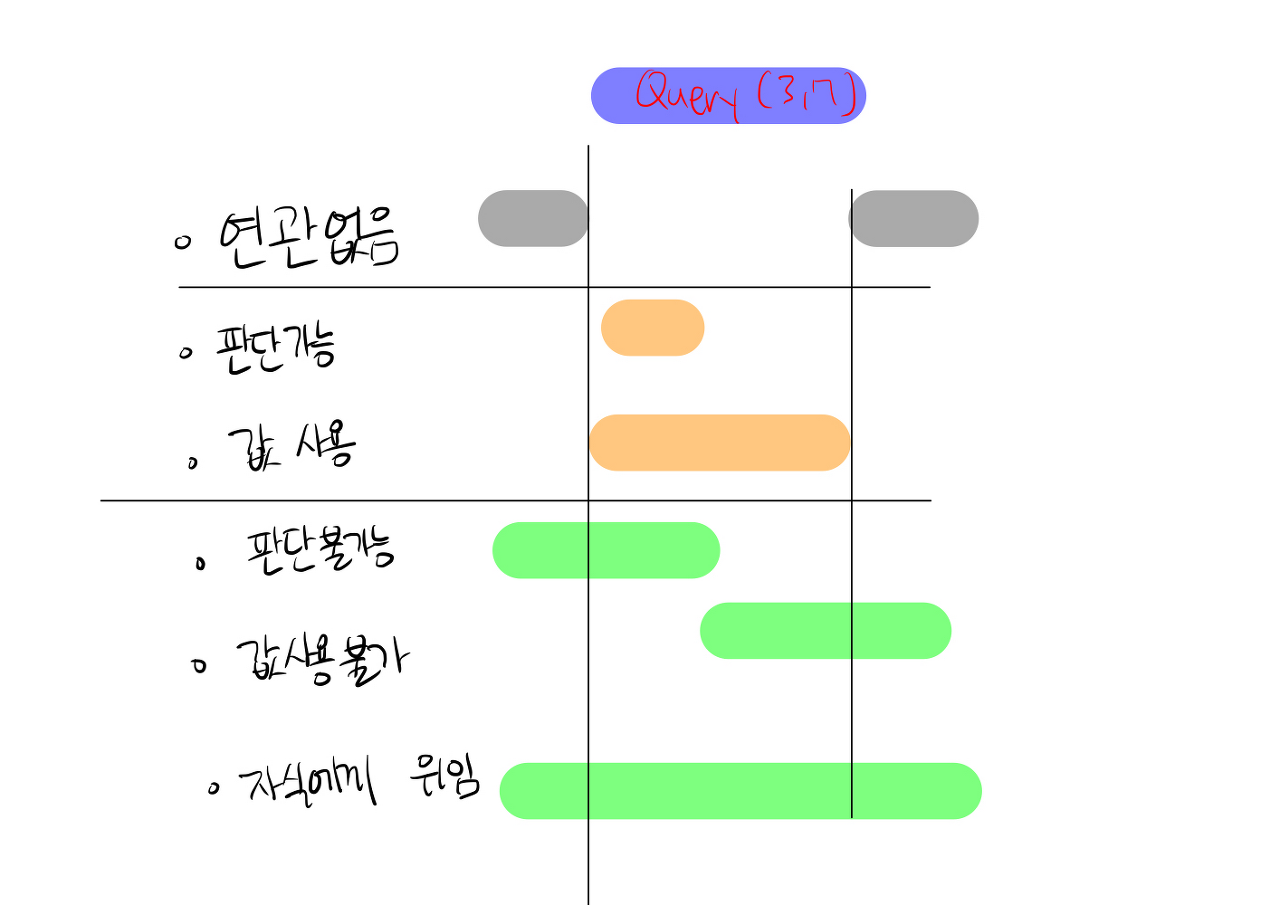
이 조건에 대해서 어떻게 행동해야하는지는 아래 코드 구현 부분에서 설명하겠습니다.
이와 같은 개념을 갖고 인덱스 트리를 이용하여 탐색할 수 있습니다.
인덱스 트리 - 쿼리 코드 구현
위에서 탐색할 때 우리는 계속해서 범위를 비교했습니다.
이 때 범위는 두 가지로 나눌 수 있었는데
- 고정된 범위 : 찾으려 하는 범위
- 동적 범위 : 점점 줄여져 가는 범위
였습니다.
저희는 다음과 같이 메서드를 구현할 수 있습니다.
long query(int left, int right, int node, int queryleft, int queryRight) {
// 연관이 없음 -> 결과에 영향이 없는 값
// 판단 가능 -> 현재 노드 값 return
// 판단 불가, 자식에게 위임, 자식에게 올라온 합을 return
}
// 연관이 없음 → 결과에 영향이 없는 값
- 연관 없음
먼저 연관이 없다.
즉, 탐색하고 있는 범위에 하나도 해당이 안되는 경우에는 과감하게 무시합니다.
만약 노드를 타고 들어간다하여도 계속해서 해당하지 않는 범위만 나오기 때문입니다.
// 판단 가능 → 현재 노드 값 return
- 판단 가능
- 값 사용
판단이 가능하다면 바로 현재 노드 값을 return 해줍니다.
만약 우리가 찾는 범위가 (3, 9) 일 때 자식 노드의 범위가 (4, 5)라면 현재 노드 값을 return 해주어 현재 노드 값 중 (4, 5) 범위만 가져옵니다.
// 판단 불가, 자식에게 위임, 자식에게 올라온 합을 return
- 판단 불가
- 값 사용 불가
- 자식에게 위임
이 때의 상황은 내가 찾는 범위도 있지만 그렇지 않은 범위도 같이 있을 때 사용합니다.
컴퓨터가 곧바로 내가 찾는 범위만 가져올 수 없기에 범위에 대해서 더 세분화된 자식에게 이 일을 넘겨줍니다.
이러한 주석들을 구현하면 아래와 같은 코드가 됩니다.
long query(int left, int right, int node, int queryleft, int queryRight) {
// 연관이 없음 -> 결과에 영향이 없는 값
if (queryRight < left || queryLeft < right) {
return 0;
}
// 판단 가능 -> 현재 노드 값 return
else if (queryLeft <= left && right <= queryRight) {
return tree[node];
}
// 판단 불가, 자식에게 위임, 자식에게 올라온 합을 return, 자식 순회
else {
int mid = (left + right) / 2;
// 왼쪽 자식 노드
long resultLeft = query(left, mid, node * 2, queryLeft, queryRight);
// 오른쪽 자식 노드
long resultRight = query(mid + 1, right, node * 2 + 1, queryLeft, queryRight);
return resultLeft + resultRight;
}
}
인덱스 트리 - 업데이트 구현
이제 갱신에 대해서 알아보겠습니다.
인덱스 트리 안에 어떠한 값을 갱신하게 되면 그 노드와 연관 되어 있는 부모 노드들도 다 갱신해줘야 합니다.
저희는 이러한 변화 같은 diff라고 하겠습니다.
또한 저희는 범위 전체를 바꾸고 싶은게 아닌 한 값만 바꾸려 하는 것이기에 범위를 찾을 범위 대신에 해당 인덱스의 값인 target을 지정하겠습니다.
target 번째 값을 a로 갱신하라는 명령이 들어오면
diff = a - tree[S + target - 1] 으로 diff를 초기화해서 사용합니다.
이때 인덱스를 보면 S + target - 1 임을 볼 수 있습니다.
이 때 S는 뭘까요 ?
사실 S는 리프 노드의 시작점입니다.
우리가 가지고 있던 인덱스 트리를 배열로 표현하면 아래와 같습니다.
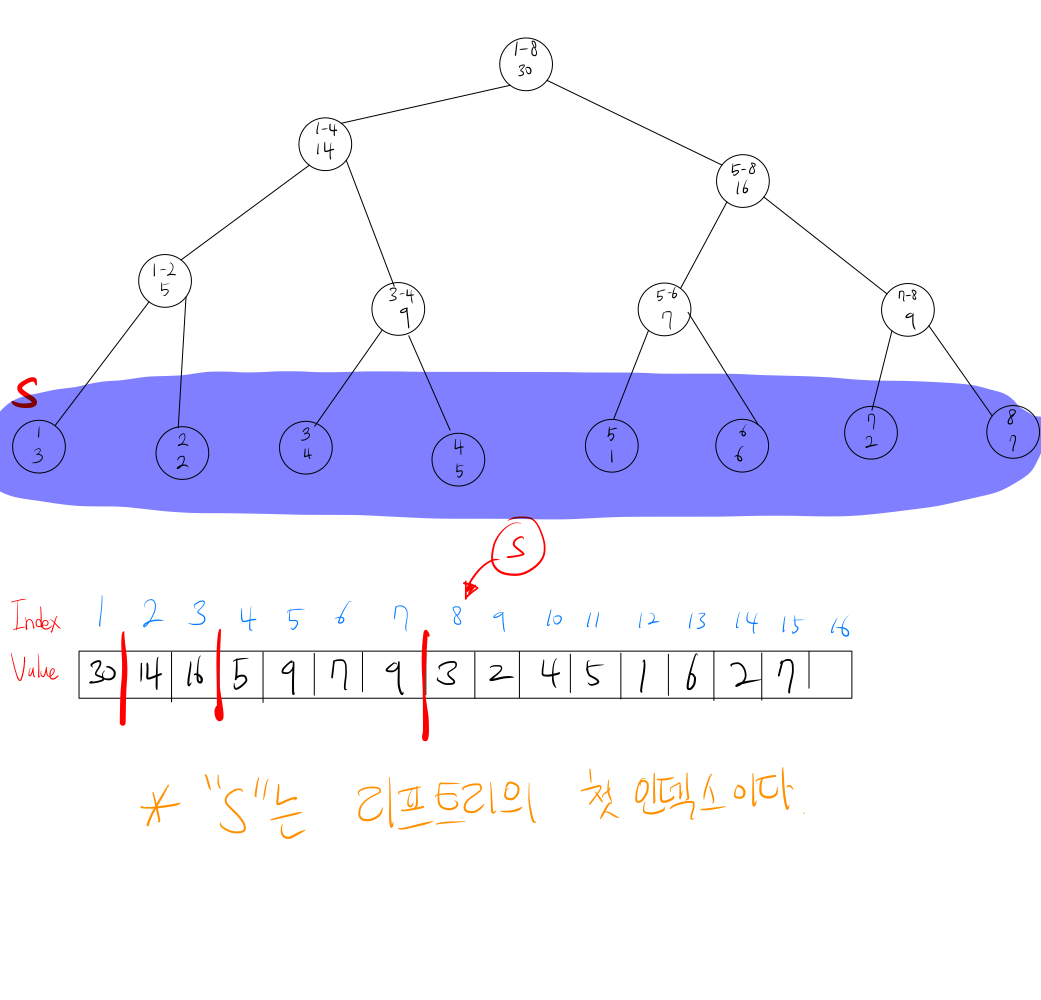
이제 다음과 같이 update 메서드가 나오게 됩니다.
void update(int left, int right, int node, int target, long diff) {
// 연관 없음
// 연관 있음 -> 현재 노드에 diff 반영 -> 자식에게 diff 전달
}
갱신도 마찬가지로 target이 범위에 연관이 있는지 없는지 판단해서 구현해야 합니다.
연관, 범위에 대한 그림입니다.
연관이 있는 노드에 대해 -=diff 하여 구간합의 값이 유지되도록 해야합니다.
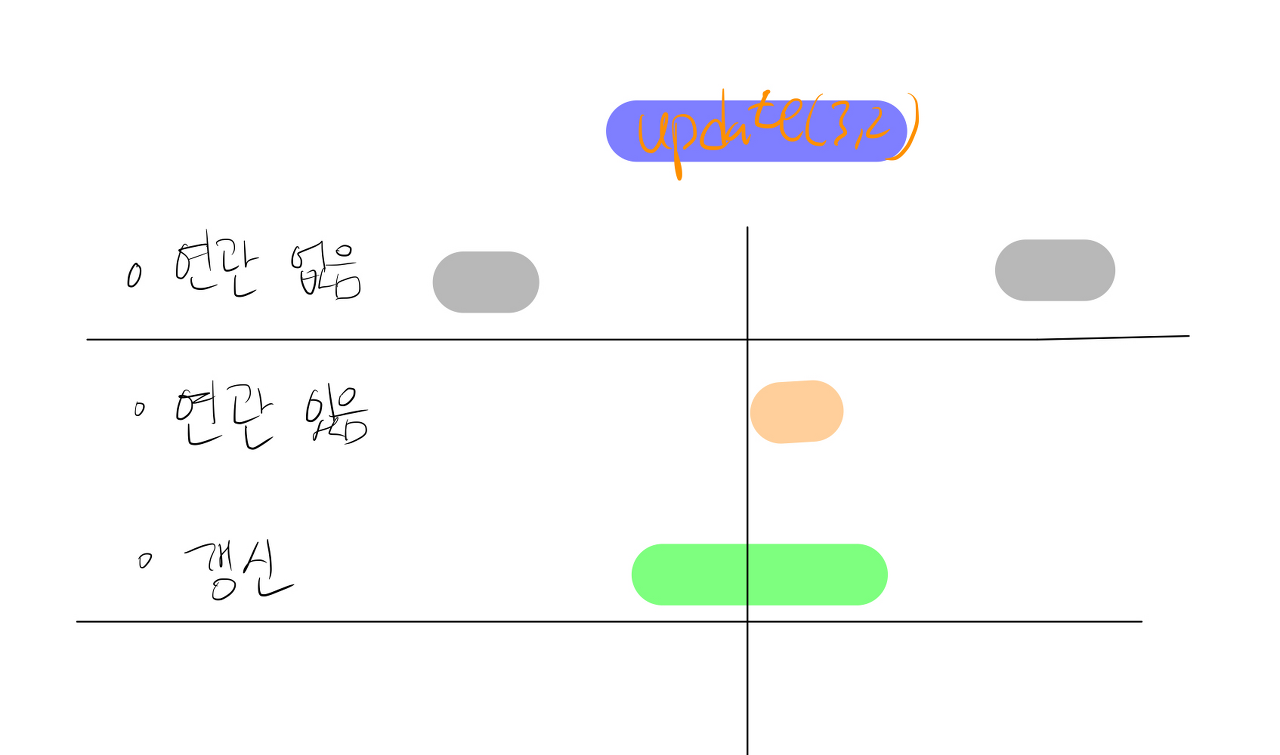
이제 조건에 맞춰 구현하면 아래와 같은 코드가 나오게 됩니다.
여기서 if(left ≠ right)는 리프 노드가 아님을 의미합니다
리프 노드의 범위는 1로 left == right이며 더 이상 내려갈 자식노드가 없습니다.
void update(int left, int right, int node, int target, long diff) {
// 연관 없음
if (target < left || right < target) {
retun;
}
// 연관 있음 -> 현재 노드에 diff 반영 -> 자식에게 diff 전달
else {
tree[node] += diff;
if (left != right) {
int mid = (left + right) / 2;
update(left, mid, node * 2, target, diff);
update(mid + 1, node * 2 + 1, target, diff);
}
}
}
응용 문제 풀어보기
2042번: 구간 합 구하기
첫째 줄에 수의 개수 N(1 ≤ N ≤ 1,000,000)과 M(1 ≤ M ≤ 10,000), K(1 ≤ K ≤ 10,000) 가 주어진다. M은 수의 변경이 일어나는 횟수이고, K는 구간의 합을 구하는 횟수이다. 그리고 둘째 줄부터 N+1번째 줄
www.acmicpc.net
2243번: 사탕상자
첫째 줄에 수정이가 사탕상자에 손을 댄 횟수 n(1 ≤ n ≤ 100,000)이 주어진다. 다음 n개의 줄에는 두 정수 A, B, 혹은 세 정수 A, B, C가 주어진다. A가 1인 경우는 사탕상자에서 사탕을 꺼내는 경우이
www.acmicpc.net

댓글